")
The automation level achievable by using Station is possible thanks to its powerful mapping engine: it allows to outline both static and dynamic rules for the extrapolation of data from various documents, starting from a sample file configured once and for all.
The type of mapper used by Station depends on the type of file to which the template is associated.
Mapping a document is really simple. For this example we will consider a PDF file (invoice), and so a specific engine will be used.
First Station offers a starting dataset to identify the data header (MasterDataset), but it is possible to define other datasets and fields associated to them.
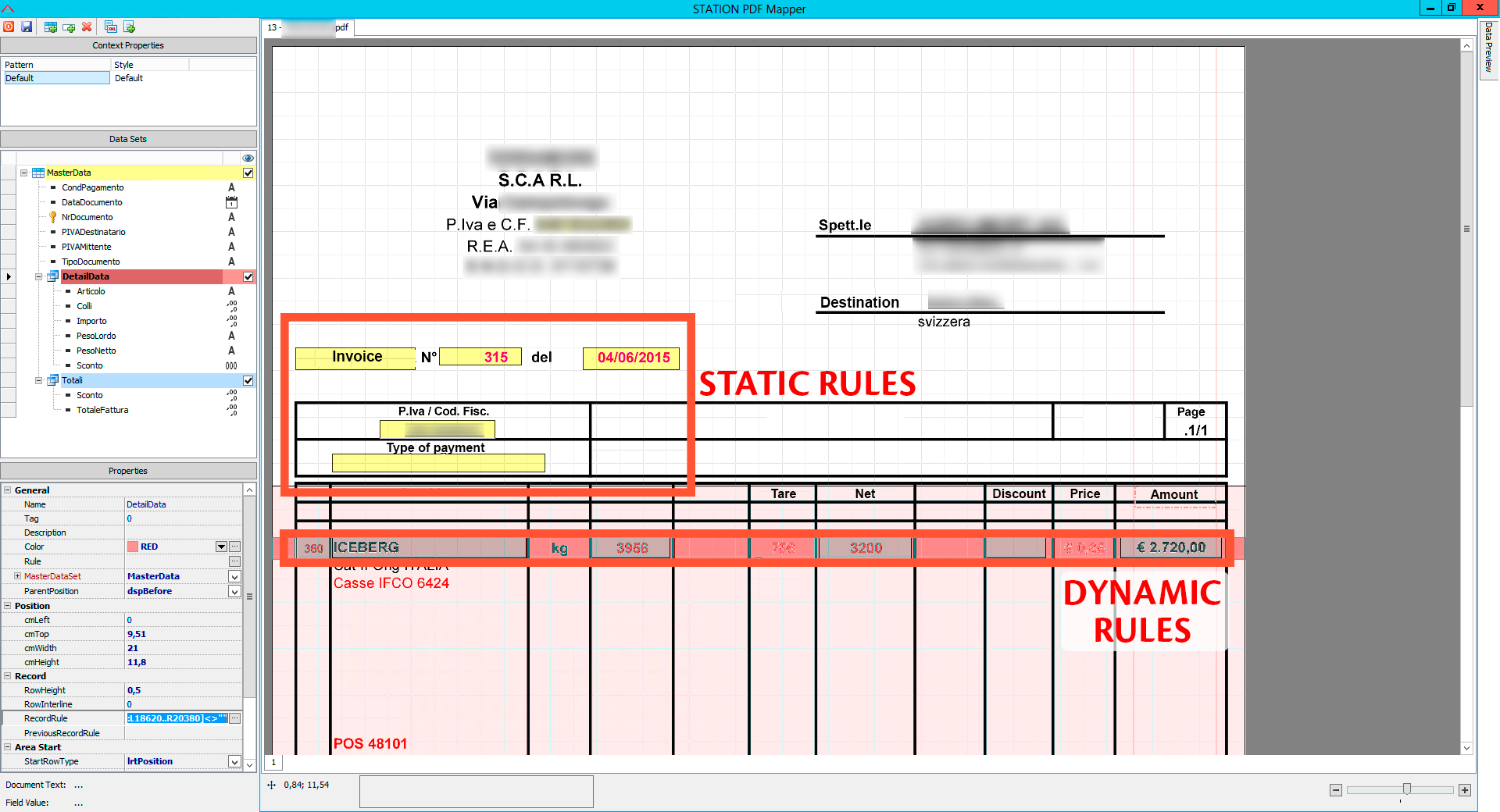
Usually data headers (here in yellow), are defined by static rules that identify the position within the document.
Row data (here in red), instead, are defined by dynamic rules, that make possible to extrapolate the required data in different situations (different articles, variable number of pages, quantity or different units of measurement, etc.)
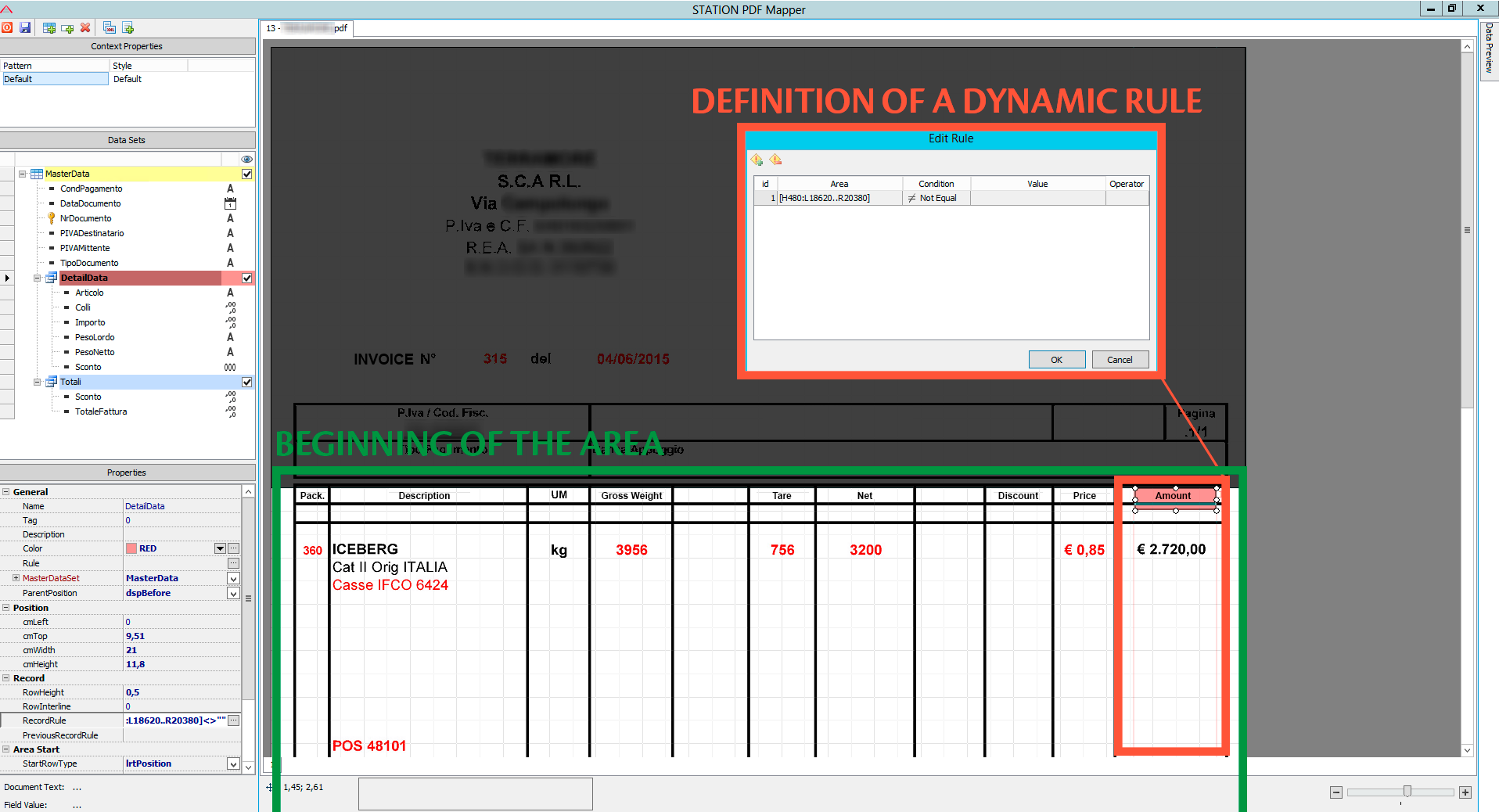
The following is an example of definition of a dynamic rule: we have specified to consider only those rows whose amount is not empty.
Not only fields rules can be dynamic, but also beginning and end areas can be related to dynamic rules to ensure the greatest flexibility possible.
The extracted data is associated to a type (integer, float, date, etc), to a dimension and to any additional rule (e.g. a startTag/endTag or a string trim)
After the definition of all fields position and datasets, it is possible to test the results in real-time (here on the right column) and to make the needed changes.

Extracted data can then be transferred to the common structure of the document (in this case an invoice), using the Data Transform module.
Into the Data Transform module you can drag and drop data extracted from the document to the common structure that will affect the following flows (upload on DB, ERP, etc.).
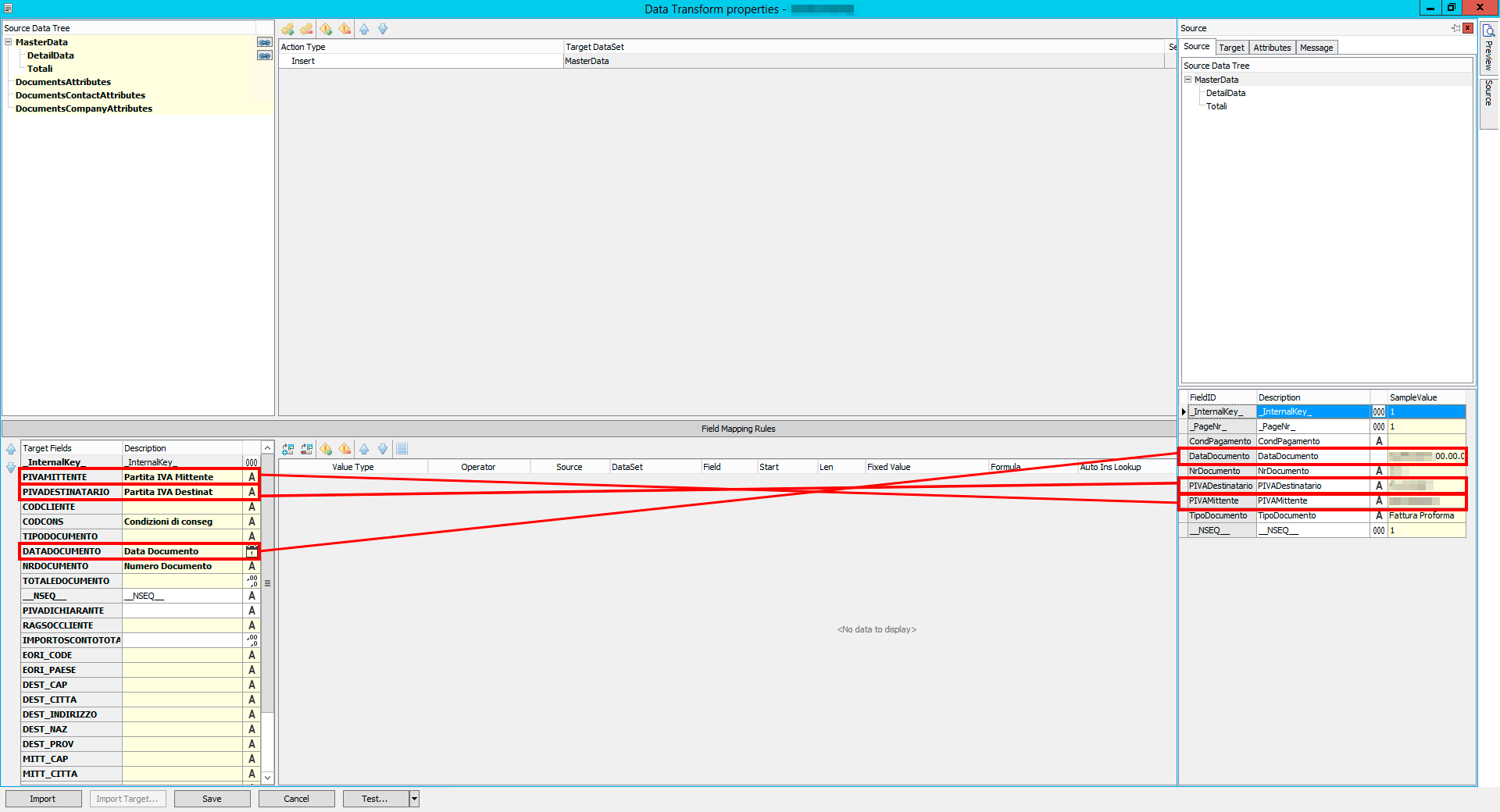
Data Transform module does not operate a mere association, but it also allows to specify further options, e.g. view conditions (to value the X field with A data rather than with the B data according to my needs), or the inclusion of scripts to manipulate the extracted data (e.g. change the time format or extract the nation from VAT)
Once the structure is completed, it will be possible to run tests to check the result and to verify that the extracted data are correct.
Now the structure is ready and it can be used by Station for further processing.